Reducing scan archive storage costs by 95 % using Kinesis Data Firehose
Introduction
Cloud-based services are no different than any other piece of software in a way that requirements change over time. Usually, they are less specific in the beginning of a service’s life. Over time, more requirements and use cases are added.
When we started our cloud journey, one of the few requirements we knew about was that the data that is sent from our customer’s scanners to the cloud via AWS IoT Core needs to be stored in a persistent and reliable way. The obvious choice was to use Amazon S3 to simply store every scan we receive as a single object.
Over time it became apparent that this approach had some severe disadvantages:
- S3 is priced per PUT request to store an object (or scan). This also means that costs will scale with the usage of our SaaS platform - something we try to avoid.
- The data analytics team had to face serious limitations caused by the storage format when they were trying to use the data to gain deeper insights. The simple storage pattern did not allow to query the data by time periods, which is a common access pattern that allows to control the amount of data in a precise way.
This led to finding a better way to solve the problem. One service offered by AWS for handling this is Kinesis Data Firehose, which is described on their website like so:
Amazon Kinesis Data Firehose is an extract, transform, and load (ETL) service that reliably captures, transforms, and delivers streaming data to data lakes, data stores, and analytics services.
IoT data is an explicitly listed use case, and so is S3 as a storage service. In addition, Kinesis Data Firehose is a fully managed, serverless offering with zero cost at no usage, which made it an interesting candidate for the task. You can learn more about the architecture of our platform in the article A 100% Silo’d architecture?.
The key feature the service has to offer turned out to be dynamic partitioning:
With dynamic partitioning, Kinesis Data Firehose continuously groups in-transit data using dynamically or statically defined data keys, and delivers the data to individual Amazon S3 prefixes by key. This reduces time-to-insight by minutes or hours. It also reduces costs and simplifies architectures.
During a quick proof of concept using the architecture in the following diagram, we found out that all our added requirements could be met in a very simple and elegant way:
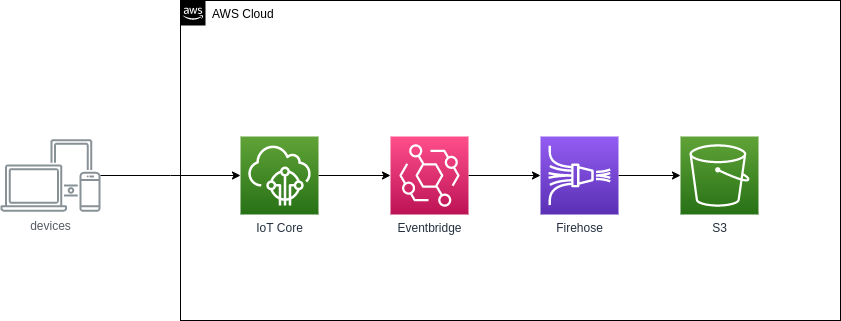
This approach allowed us to:
- reduce the amount of code for the entire setup to a little over 200 lines of infrastructure code
- cut the S3 costs by 95%
- improve data analytics query performance via AWS Glue by three to four orders of magnitude, since the storage format is optimized for exactly this purpose
The current implementation of the event archive serves a rather generic purpose by design, while the approach also lends itself well to fulfill other use cases. Whenever a new demand arises for processing the customer’s data, Kinesis Data Firehose offers integrations with services such as Amazon Redshift, Amazon OpenSearch Service, Kinesis Data Analytics or generic HTTP endpoints.
Example infrastructure
The following section shows an example infrastructure for a complete event archive for IoT messages. The code snippets shown here are only showing relevant parts for the sake of brevity. You can find the whole source code in the corresponding github repo.
The key resources contained in the template are:
AWS::S3::BucketAWS::Events::RuleAWS::KinesisFirehose::DeliveryStreamAWS::IoT::TopicRule
The S3 bucket will serve as the event archive and comes in a fairly standard configuration, as shown in listing 1:
EventArchiveBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub "ioteventarchive-${AWS::AccountId}"
[...]
The IoT Core topic rule will serve as an example input of events to give a somewhat realistic scenario. Its purpose is to send events to a Lambda function which in turn sends an event to the Eventbridge event bus that are stored in the archive. In practice, the architecture is not limited to IoT events - it can be used for all types of events. Listing 2 shows an example topic rule:
IotIngestionRule:
Type: AWS::IoT::TopicRule
Properties:
RuleName: iot_ingestion_rule
TopicRulePayload:
AwsIotSqlVersion: "2016-03-23"
RuleDisabled: false
Sql: SELECT timestamp() as time_received FROM 'iot/+'
Actions:
- Lambda:
FunctionArn: !GetAtt IngestionLambda.Arn
The next resource we create is an event rule which picks up the events we are interested in and sends them to the Kinesis Firehose delivery stream for processing. Again, which events you choose to send to the archive is completely up to you. The only restriction you need to keep in mind is that depending on how you process the events in the delivery stream, you need to make sure that the contents of the events are suitable. A more detailed explanation of what this means will follow a little bit later… In our example, we make sure that the events contain an attribute time_received in the detail field.
Listing 3 shows an example event rule with its only target, the delivery stream:
ArchiveIngestionRule:
Type: AWS::Events::Rule
Properties:
Name: ioteventarchive-ingestion-trigger
Description: |
This rule taps into the eventbridge events to archive them by sending them
off to Kinesis Data Firehose.
EventBusName: !Ref EventBusArn
EventPattern:
source:
- iot.ingestion
detail-type:
- scan-event
State: ENABLED
Targets:
-
Arn: !GetAtt IotEventDeliveryStream.Arn
Id: TargetIngestion
RoleArn: !GetAtt IngestionRuleRole.Arn
InputPath: $.detail
DeadLetterConfig:
Arn: !GetAtt DeadLetterQueue.Arn
Note that an SQS queue has been configured via the DeadLetterConfig property of the rule target. This way, we can make sure that events that fail to be processed are not lost.
The final and most relevant resource we create is the delivery stream itself. Listing 4 shows the configuration:
EventArchiveDeliveryStream:
Type: AWS::KinesisFirehose::DeliveryStream
Properties:
DeliveryStreamName: ioteventarchive-ingestion
DeliveryStreamType: DirectPut
DeliveryStreamEncryptionConfigurationInput:
KeyType: AWS_OWNED_CMK
ExtendedS3DestinationConfiguration:
BucketARN: !GetAtt EventArchiveBucket.Arn
BufferingHints:
SizeInMBs: 64
IntervalInSeconds: 60
RoleARN: !GetAtt IngestionDeliveryStreamRole.Arn
CompressionFormat: GZIP
Prefix: data/year=!{partitionKeyFromQuery:year}/month=!{partitionKeyFromQuery:month}/day=!{partitionKeyFromQuery:day}/
ErrorOutputPrefix: ingestion-failed/!{firehose:error-output-type}/year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/
DynamicPartitioningConfiguration:
Enabled: true
RetryOptions:
DurationInSeconds: 60
ProcessingConfiguration:
Enabled: true
Processors:
- Type: MetadataExtraction
Parameters:
- ParameterName: MetadataExtractionQuery
ParameterValue: '{year : ((.time_received / 1000) | strftime("%Y")), month : ((.time_received / 1000) | strftime("%m")), day : ((.time_received / 1000) | strftime("%d"))}'
- ParameterName: JsonParsingEngine
ParameterValue: JQ-1.6
- Type: AppendDelimiterToRecord
Parameters:
- ParameterName: Delimiter
ParameterValue: "\\n"
Let’s go through the relevant parts here:
The ExtendedS3DestinationConfiguration defines the delivery stream target - S3 in this case. The BufferingHints parameter sets the
delay after which data is written to the target bucket in BucketARN: whenever 64 MByte were received or latest after 60 seconds.
The CompressionFormat tells Firehose to compress the data, further saving space.
The Prefix parameter tells the delivery stream to store the events under a date specific prefix. This is especially powerful
in combination with the ProcessingConfiguration. As you can see, the Prefix contains references to the values that are
extracted from the actual event data:
year=!{partitionKeyFromQuery:year}
These values are set when Firehose processes the events. The ProcessingConfiguration tells Firehose what to do to process
incoming events. In the example, we make use of what AWS call metadata extraction. This is essentially using jq
to process json events. By defining a Processor of type MetadataExtraction and setting the two parameters MetadataExtractionQuery
and JsonParsingEngine for the processor we tell it to run the jq query given in the MetadataExtractionQuery parameter using the jq 1.6 engine.
When doing so, the attributes in the resulting json are accessible in the Prefix which defines the way we store the events.
Summary
This article shows how to make use of some advanced Kinesis Firehose features to create an optimized storage format for incoming IoT events. The resulting format is easy to query and the setup works without maintaining any custom-written lambda functions.