A 100% Silo’d architecture?
When we’re developing the backend architecture for Insight, we are building a rather unique thing. It’s serverless, built on python and AWS (you’re with me so far, right?) - and we have it running in more than 2,000 AWS accounts.
For each customer that is using the insight platform, we provision and deploy a completely separate AWS account. We went full SILO on this thing.

Before I go into the benefits of that architecture, let me recap the different deployment methods for multi-tenanted systems - especially in a public cloud setting.
Building a SaaS software, you (usually AND hopefully) have the challenge to maintain a system for multiple customers/entities. They generally get to see and do something similar with your software (depending on the subscription plan etc) BUT each entity will generally have their own data, that should stay private to them. Providing this capability is usually referred to as “tenant isolation”. A very common pattern is that during login some kind of identifier is passed through the application. Data is then marked with that identifier, and on each operation, this identifier (the “tenant ID”) is checked.
If you followed this vague example along, you’ll notice that the way a request passes through the system would be the same for each customer - only the data it operates on is different per customer, one database, one application server, etc. If one customer uses too much resources, it would “bleed” over onto the other customers, potentially denying them service. AWS refers to this as a “pooled” resources -all customers (or at least a group) share the infrastructure that provides a service. The tenant isolation is done in code.
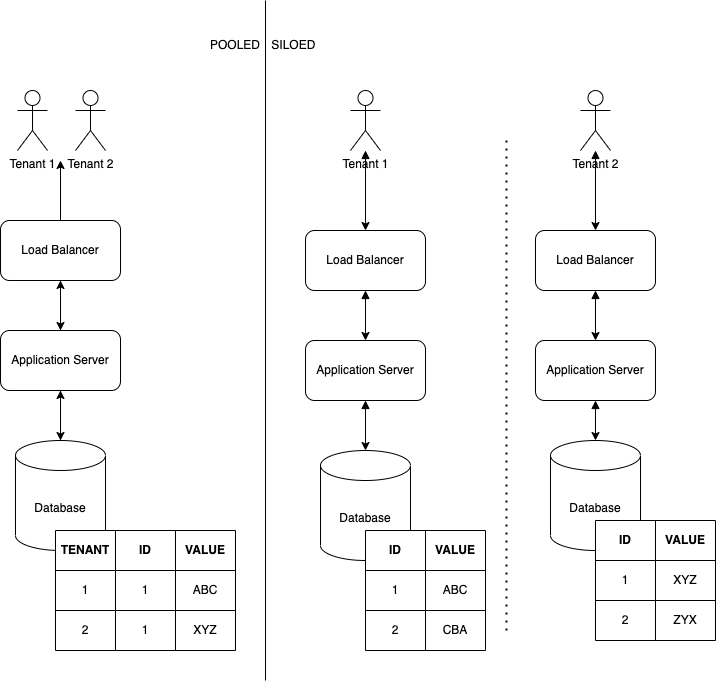
Opposite, you’ve got the Silo approach. Instead of having multiple customers share the infrastructure, each customer gets their own deployment. Separation is done using the underlying infrastructure, not via (custom) application code. So one database per customer, one application server, etc.
In reality you will often encounter a mixture of these two models (one database per customer, but one central application server (cluster)) - but we went as far as we could with a full silo architecture.
We take the lowest level of isolation that a public cloud provider has, the “account”, and use this as our tenant isolation technique. For each new tenant, we’ll setup a separate AWS account, deploy the complete application infrastructure into it. We therefore get tenant isolation without building it ourselves - the AWS account system. AWS calls this a “multi-account setup”
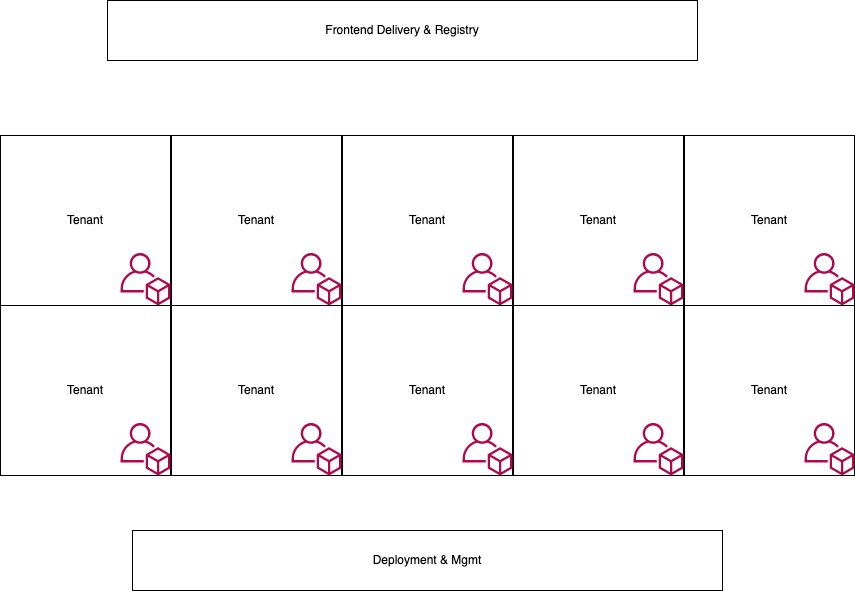
We ended up having a small number of “central” services that span the complete network: the delivery of our Single-Page Application frontend, a small registry service to identify tenants and several services related to deployment and tenant lifecycle management, but the complete application logic and data handling is happening in each tenant - 2000 times.
The benefits are easy to list:
- Complete control over each customers data & services. We can guarantee that no tenant has access to any others data as long as the AWS account system is not compromised. This makes discussion about data privacy and security with large corporate users VERY easy.
- We can also be pretty certain that one tenant can NOT bring down other tenants, as long the as AWS AZ/Region is not impacted.
- Cost measurement & assignment is as easy as using the AWS cost explorer
- During development, you don’t have to think about tenants, tenant IDs - if you can reach a resource it’s from the “current” tenant.
- Setting up multiple deployment stages is kind-of built in. For our PR check, we spin up a complete “production like” environments, just to tear it down afterwards. And setting that up was really pretty straightforward, as it’s basically just another customer account.
However as you might have already understood, this type of architecture comes with two huge issues:
- Cost: the smallest EC2 instance would cost us at least 6000$ per month
- Maintenance/Effort: how do you know that a single endpoint for a single customer is up when you have ~6000 individual endpoints to check?
(isn’t it always these two?)
I’ll go much deeper into this in a follow-up article.
Conclusion
Going all in on a serverless multi-account architecture has been … interesting. There are huge benefits, but also huge drawbacks with this type of architecture (which I guess is true for all architectures). For us, the security and data privacy benefits outweigh the drawbacks. We’ve had to invest a decent amount into the tooling to make this happen, but so far, we’re still really happy with going 100% silo, even if I put different words into Ben’s mouth above.