Returning Binary Data via Rest from Lambda
If you are building a Rest-API via AWS Lambda, you probably use AWS API-Gateway. And you might have already tried to return an image or some other piece of binary data via this way. Turns out that this is non-trivial, as you can read all over the web. In recent months, we found that a combination of API-Gateway and the new Lambda Function URLs work great for these purposes.
Background
As the docs state, API-Gateway follows the RESTful model strongly:
First set content types as “binary media types” in your API-Gateway config (yes, that’s the global config per API, not per resource) and implement your Lambda to return binary data. To do so, if you’re using lambda-proxy integration, you Base64-encode your data. And if you don’t, you should really switch to lambda-proxy integration.
Then, and this is the crucial point, the requester has to apply the correct Accept header to get binary data in return - otherwise, they’ll get text.
BUT what happens if the thing requesting here is something you don’t control? Like maybe (gasp) a browser?
It turns out that the only way you can return binary data (for example an image or some non-text file) via API-Gateway to browsers is by setting the Binary Media Types Setting in your API config to */* - which means that every content type will be outputted as binary if you (for some reason) return it to API-Gateway base64 encoded and not as String.
Let’s take a small example with two lambdas & resources/endpoints: REST call to get a list of files and then a call to get an individual file. To download or display these files with an arbitrary extension in the browser, you would need to set the “Binary Media Types” of the API to */* .

When you’re setting out on your api building journey and you know this, you can build around this and make it work. But if you only stumble into this if your API already has a bunch of resources and functions - chances to break things are huge - I wouldn’t recommend it.
The solution you often find for this is to return S3 presigned URLs in the first call and then let the browser interface directly call S3.
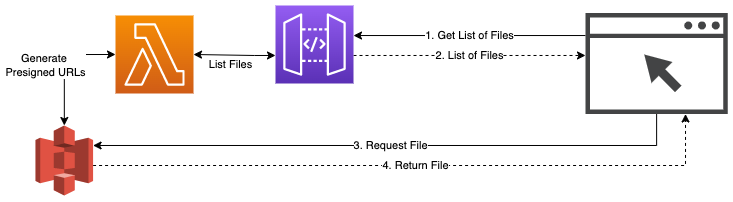
Up to now, this was often the best available solution. However, it doesn’t work well with dynamic files that are generated on-the-fly, it exposes your S3 bucket “backend” to the users of your API (adding a second endpoint) and (yes, this was a serious issue for us) the S3 presigned URLs are really long and unwieldy.
For completeness, you could also use S3 object lambdas to do a lot of these things (as outlined here) - but then, you’d throw another place where your code is executed into the mix.
Function-URL Solution
With their recent release in April 2022, AWS Lambda Function URLs are a much better option here.
Quick refresher on function URLs: Instead of exposing your lambdas via a (central) API-Gateway, you define a function URL for each lambda. Via this function URL, the lambda is then exposed as an HTTP API. The code is the same as working with proxy-integration for API gateway.
Testing this, we found that the function URL “integration” does not need any Accept or other headers in order to do what is expected. If binary data is sent from the lambda, it’s passed on as binary data.
So our solution drawing goes back much closer to the original - the list returned from the first Lambda includes a list of file-urls that are served via the function-URL of the GetFile lambda.
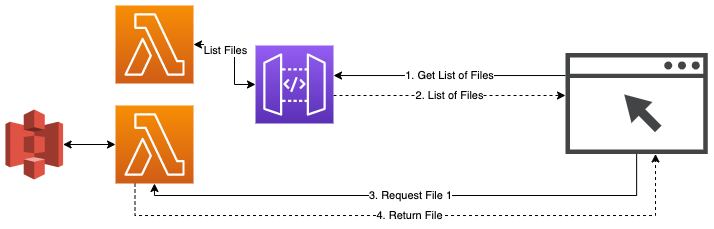
While this also adds a second endpoint to your application, S3 is hidden behind the lambda. Any kind of dynamic generation can be done in the lambda before the data is returned. Code wise, there will be no changes necessary in the GetFiles lambda as the Function URL uses the proxy integration method.
However, two big caveats remain: Authentication and Rate-Limiting.
Authentication:
If access to the file should be controlled, you have to either build it on your own or rely on IAM authentication. But seriously, if you’re using IAM authentication (sigv4), you probably don’t have an issue with the s3 method above.
As you want to support standard browsers, JWT-Tokens in the Authentication header are out as well (how would you get them into the request) so you’ll need to implement a “token” pattern. We write a token when the “List Files” request is made and return a url with the token: $function-url/$file_to_be_read?token=$token. When retrieving the file, the token is “burned”.
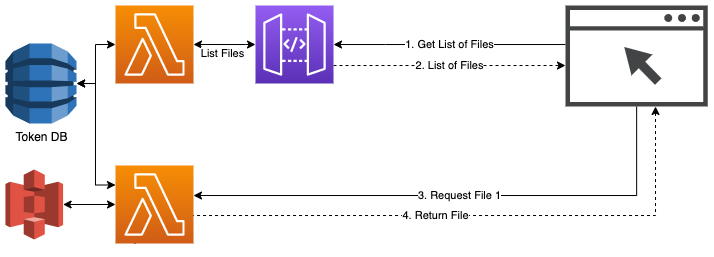
Rate-Limits
As far as we know, there is currently no way to rate-limit your lambda function URLs. As stated in Lambda quotas - AWS Lambda up to 10x of your concurrent executions would be possible here. Which could potentially cause a denial of service, because this way the full limit of available lambda executions for an account can be eaten up. On the other hand, it would probably NOT drain your bank account, at least if you have the token-based approach described above implemented.
With the standard 1000 concurrent executions (which would kick in after a short burst), a runtime of 100ms and a single dynamodb query to verify that the token is used you would pay ~5$ per hour or 110$ per day.
But yes, running this without any monitoring/cost budgets is a bad idea. But then again, everything in the cloud is 🙂.
Conclusion
While some features of the function URLs are definitively still lacking, we see them as the best way of supplying (dynamic) files via Lambdas for now.